
- 广州子锐机器人技术有限公司
- 服务热线:020-82000787(8:30-17:30)
- 联系手机:15889988091(非工作时间)
- 座机:020-82000787
- 传真:020-32887675
- 邮箱:gz@zr-robot.com
- 广州市番禺区东环街金山谷创意八街1号109
- 当前位置:首页 > 机器人资讯 > 机器嗓音里的赛车场:我们离完美的AI之声还有多远?
机器嗓音里的赛车场:我们离完美的AI之声还有多远?
人类与AI的对话频率,正在进入一个前所未有的大爆炸时代。
无论是智能手机里的语音助手、有买有送的智能音箱,还是千娇百媚的智能机器人或者地图导航,总有一款声音萌动你心。这些生活中随处可见的声线,背后其实都是靠一项核心技术来支撑的:语音合成TTS(Text-To-Speech),即将文字转化为声音。
在一般情况下TTS并不受到广泛关注。很多智能语音相关产品的发布会上,它甚至不会占用超过一页PPT的篇幅。但实际上,TTS对于整个AI语音交互的体验触发,起到了决定性的作用:用户听到什么声音,直接影响到AI在他心中的“三次元化”形象。
比如我一个朋友就是因为志玲姐姐嗲嗲的配音,成为了地图导航的死忠粉。而在经典的AI电影《Her》里,人工智能系统OS1就拥有斯嘉丽约翰逊的迷人声线,让男主人公为之倾倒,一段人与AI的虐恋就此展开。
语音合成,为机器注入了一种人格化的魅力,也让人类更愿意与之建立亲密关系。这也意味着,在商业价值都要靠黏住用户来实现的当下,TTS能力将成为各个语音场景输赢的命脉。尽管企业对TTS的需求是如此迫切,但从学术到产业应用之间,TTS依然存在着大片的技术空白。相近的技术原理和前沿算法探索之后,每家公司的解决方案、解决能力都千差万别。二者叠加之下,导致TTS变成了一个巨大的赛场。
本文希望剖析这个并不为大众熟知的赛道,透视一下是什么决定了机器如何说话,决定了用户耳朵的体验与舒适度,又有哪些玩家凭借TTS撬开了智能语音的富矿。
那场极速的温柔:让机器听上去像人,是AI公司的首要奔跑方向
最近,网上流行起了一种新的搞笑玩法:扮演机器。比如,用百度翻译的语音包跟游戏中的队友说话,浓烈的机械味怕是会被队友忍不住一枪爆头。
与此同时,一个娘化的AI形象“绊爱”也迅速走红,被粉丝们亲切地称为“爱酱”。它有着少女一样的形象,能够像人类一样交流,言语之间还会时不时流露出作为AI的志得意满。对过度机械的语音无情调侃,为高度人性化的语音疯狂打call,可以说是普通人对TTS的下限与上限最为直接的反应了。
从中不难看出,TTS的核心赛道,就在于如何让机器的声音听上去韵律自然、情感充沛。说白了,就是如何在机器声音中注入人性。这个听起来很模糊的需求,现实中只能通过TTS多个技术层次的逐步通关来实现。
综合整个流程来看,目前有两方面的工作是AI公司努力的核心方向:
用心的语料库,正在成为TTS发动机
如何用更少的语料合成更自然的高质量语音,可能是未来TTS的技术攻坚方向。
目前看来,更有情感表现力和精准韵律的声音,一定是通过庞大精准的语料库直接拼接产生的。这背后隐藏的,是AI公司正在比拼构建语料库的投入成本与产品精神。
比如苹果就请来了专业配音员苏珊·贝内特(Susan Bennett)为Siri录制原始语料,而微软小娜Cortana的声音则来自演员简·泰勒(Jen Taylor),曾为《光晕》游戏中的角色Cortana配音。国内,高德则邀请了林志玲、郭德纲、TFBOYS、罗永浩、黄晓明、高晓松等众多流量担当来录制导航语音包。
而为小米音箱、喜马拉雅音箱、美的音箱等智能硬件提供服务的AI女声,则是猎户星空从300个女声中投票海选出来的。为了能让AI声音更为流畅自然地进行中英文混说,猎户星空专门找了一个和中文声源发音很像的女孩子来录制英语语料包。
从大量发音人的挑选,语料的精心打磨,以及对用户场景的深度适配,好的TTS前端数据处理能力,是今天区分这个细分领域产业地位的核心。
用算法探索“听着舒服”的边界
解决了基础音源和庞大语料库还远远不够。今天的TTS领域,普遍前进方向是基于相似的模型,在细节上带来TTS效果优化。这个领域构成了AI技术公司在TTS上的算法优势,百度、微软等都在重磅押注。
简单来说,就是通过系统对输入的文本进行分析,获得合成语音的基本单元信息,从标注好的语音库中挑选出最合适的语音单元,根据需求进行一定的修改和调整后,经过波形拼接的方式获得合成的语音。
目前,DeepMind最新的深度生成模型WaveNet,改变了传统的拼接法,而是选择直接对音频信号的原始波形进行建模,一次处理一个样本,来产出更为自然的声音。
目前,WaveNet已经能够模拟任何人类的语音,并且将机器语音合成的表现与人类之间水平的差距至少缩减了50%。中国这边,百度正在研究用讲话人编码(speaker encoding)技术来进行自然语音的生成。
简单来说,讲话人编码器已经学会了把不同人说的话分别聚类,更好地模仿讲话人的声音特点。比如,机器能从口音判断出,讲话者是一个来自北美的男性还是来自英国的男性,从而更逼真地还原出原音。
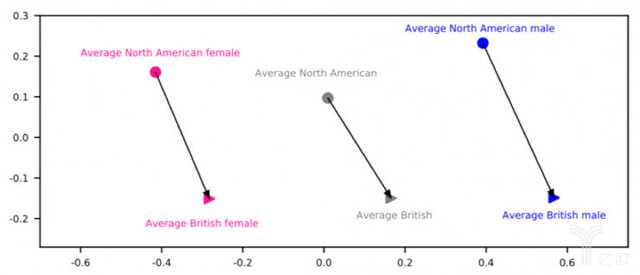
猎户星空则是通过更多层级的标注体系,来进行语音特征单元的提取。目前可以从声韵母层、音节层、词层、韵律词层、短语层和语句层6个层级,让合成后的语音在上下文韵律信息及准确度上更加完善,听起来也就更符合真人的发音习惯。
总而言之,好的TTS算法,正成为如今区分语音合成领域产业地位的核心。
训练成本之争:AI界的另一个方法,是让机器用你的声音开口
TTS的另一个赛道,是如何让机器低成本地学习用户的声音。
让更多的明星,甚至普通人的声音都可以在终端设备中苏醒,这个技术能力具有广泛的市场想象力。但是,采用明星的声音,往往需要大量语料的录入和拼接。录入时间过长不说,还需要在专业指导下完成。合作的明星要录制几千句,时间跨度动辄几个月,耗资不菲。
即便如此折腾,也难以覆盖全部细分应用领域。在某些衔接处,往往会出现机械拼凑的生涩感。不但阻碍了明星声音进入泛化设备场景,更让普通人对录入自己的声音望而却步。
所以如何降低训练成本,用更少的语料达成声音学习和语音生成,是这条赛道的关键。
最近,百度就发布了自己在语音合成方面的最新成果,可以通过“语音克隆”模仿数千个不同的声音,每个说话者需要不到一个半小时就能完成数据训练。
